

این عنوان عمدا گمراه کننده است – اما فقط تا آنجا که به استفاده از اصطلاح “ChatGPT” مربوط می شود.
“ChatGPT-like” به جای توصیف سیستم به عنوان “مدل تولید متن مانند GPT-2 یا GPT-3” فوراً به شما، خواننده، امکان می دهد تا نوع فناوری مورد نظر من را بدانید. (همچنین، دومی واقعاً قابل کلیک نیست…)
آنچه ما در این مقاله به آن نگاه خواهیم کرد، یک مقاله قدیمی تر، اما بسیار مرتبط گوگل از سال 2020 است.مدلهای تولیدی پیشبینیکنندههای بدون نظارت کیفیت صفحه هستند: یک مطالعه در مقیاس عظیم“
مقاله در مورد چیست؟
بیایید با توضیحات نویسندگان شروع کنیم. آنها موضوع را اینگونه معرفی می کنند:
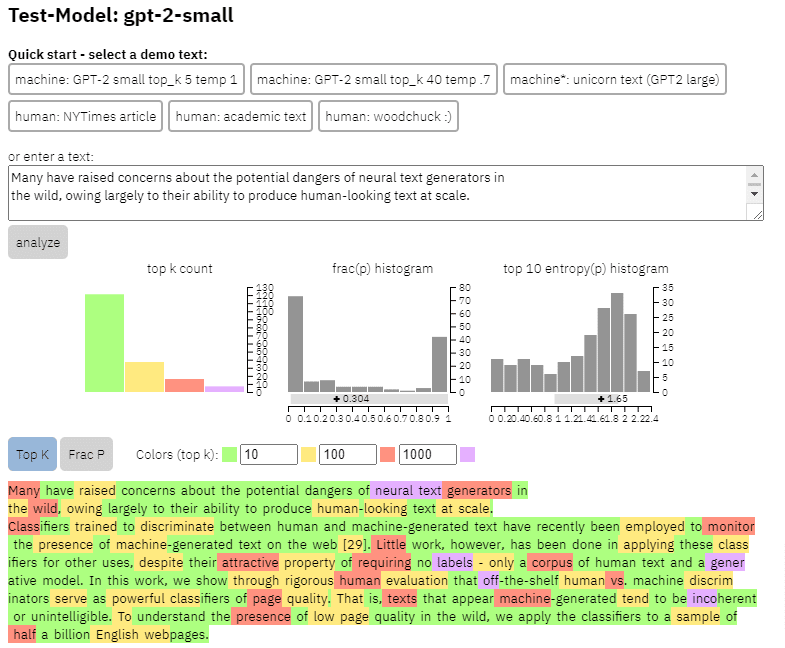
«بسیاری نگرانیهایی را در مورد خطرات بالقوه مولدهای متن عصبی در طبیعت مطرح کردهاند که عمدتاً به دلیل توانایی آنها در تولید متنی شبیه به انسان در مقیاس است.
طبقهبندیکنندههایی که برای تمایز بین متن تولید شده توسط انسان و ماشین آموزش دیدهاند، اخیراً برای نظارت بر وجود متن تولید شده توسط ماشین در وب استفاده شدهاند. [29]. با این حال، کار کمی در استفاده از این طبقهبندیکنندهها برای کاربردهای دیگر انجام شده است، علیرغم ویژگی جذاب آنها که نیازی به برچسب ندارند – فقط مجموعهای از متن انسانی و یک مدل تولیدی. در این کار، ما از طریق ارزیابی دقیق انسانی نشان می دهیم که تفکیک کننده های موجود در قفسه انسان در مقابل ماشین به عنوان طبقه بندی کننده قوی کیفیت صفحه عمل می کنند. به این معنا که متن هایی که به نظر می رسد توسط ماشین تولید شده اند، نامنسجم یا نامفهوم هستند. برای درک وجود کیفیت پایین صفحه در طبیعت، طبقهبندیکنندهها را در نمونهای از نیم میلیارد صفحه وب انگلیسی اعمال میکنیم.»
آنچه آنها اساساً می گویند این است که آنها دریافته اند که طبقه بندی کننده های مشابهی که برای تشخیص کپی مبتنی بر هوش مصنوعی توسعه یافته اند، با استفاده از مدل های مشابه برای تولید آن، می توانند با موفقیت برای شناسایی محتوای با کیفیت پایین استفاده شوند.
البته این موضوع ما را با یک سوال مهم روبرو می کند:
آیا این است علیت (یعنی آیا سیستم آن را انتخاب می کند زیرا واقعاً در آن خوب است) یا همبستگی (به عنوان مثال، آیا بسیاری از هرزنامه های فعلی به گونه ای ایجاد می شوند که به راحتی با ابزارهای بهتر به آن دسترسی پیدا کنید)؟
با این حال، قبل از اینکه به بررسی آن بپردازیم، اجازه دهید به برخی از کارهای نویسندگان و یافته های آنها نگاه کنیم.
راه اندازی
برای مرجع، آنها در آزمایش خود از موارد زیر استفاده کردند:
- سه مجموعه داده Web500M (نمونهگیری تصادفی از 500 میلیون صفحه وب انگلیسی)، خروجی GPT-2 (250 هزار تولید متن GPT-2) و Grover-Output (آنها به صورت داخلی 1.2 میلیون مقاله با استفاده از از پیش آموزش دیده تولید کردند. مدل Grover-Base، که برای شناسایی اخبار جعلی طراحی شده است).
- پایه هرزنامه، یک طبقه بندی آموزش دیده بر روی مجموعه داده های ایمیل هرزنامه Enron. آنها از این طبقهبندیکننده برای تعیین شماره کیفیت زبانی که اختصاص میدهند استفاده کردند، بنابراین اگر مدل مشخص کند که یک سند با احتمال 0.2 هرزنامه نیست، امتیاز کیفیت زبان (LQ) اختصاص داده شده 0.2 بود.
دریافت خبرنامه جستجوی روزانه بازاریابان به آن تکیه می کنند.
نکته ای در مورد شیوع هرزنامه
من می خواستم سریعاً در مورد یافته های جالبی که نویسندگان به طور تصادفی به آنها دست یافته اند بحث کنم. یکی در شکل زیر نشان داده شده است (شکل 3 از مقاله):

توجه به امتیاز زیر هر نمودار مهم است. عددی به سمت 1.0 به سمت این اطمینان می رود که محتوا هرزنامه است. آنچه ما در آن زمان می بینیم این است که از سال 2017 به بعد – و در سال 2019 افزایش یافت – اسناد با کیفیت پایین رواج یافت.
علاوه بر این، آنها دریافتند که تأثیر محتوای با کیفیت پایین در برخی از بخشها بیشتر از سایر بخشها است (به یاد داشته باشید که نمره بالاتر نشان دهنده احتمال بالاتر هرزنامه است).

سرم را روی دو تا از اینها خاراندم. واضح است که بزرگسال منطقی است.
اما کتاب و ادبیات کمی غافلگیر کننده بود. و سلامت هم همینطور بود – تا زمانی که نویسندگان ویاگرا و دیگر سایتهای «محصولات سلامت بزرگسالان» را به عنوان «سلامت» و مزارع مقاله را به عنوان «ادبیات» معرفی کردند.
یافته های آنها
جدا از آنچه در مورد بخشها و افزایش در سال 2019 بحث کردیم، نویسندگان موارد جالبی را نیز یافتند که سئوکاران میتوانند از آنها بیاموزند و باید به خاطر داشته باشند، بهویژه وقتی شروع به تکیه بر ابزارهایی مانند ChatGPT میکنیم.
- محتوای با کیفیت پایین معمولاً طول کمتری دارد (به حداکثر 3000 کاراکتر).
- سیستمهای تشخیص آموزش دیده برای تعیین اینکه آیا متن توسط یک ماشین نوشته شده است یا نه نیز در طبقهبندی محتوای سطح پایین و سطح بالا خوب هستند.
- آنها محتوای ما را که برای رتبه بندی طراحی شده است به عنوان یک مقصر خاص می نامند، اگرچه من گمان می کنم که آنها به زباله هایی اشاره می کنند که همه ما می دانیم که نباید آنجا باشد.
نویسندگان ادعا نمی کنند که این یک راه حل تمام و کمال است، بلکه یک نقطه شروع است و من مطمئن هستم که آنها در چند سال گذشته نوار را به جلو برده اند.
یادداشتی در مورد محتوای تولید شده توسط هوش مصنوعی
مدل های زبانی نیز در طول سال ها توسعه یافته اند. در حالی که GPT-3 در زمان نگارش این مقاله وجود داشت، آشکارسازهایی که آنها استفاده می کردند بر اساس GPT-2 بودند که یک مدل به طور قابل توجهی پایین تر است.
GPT-4 احتمالاً در گوشه و کنار است گنجشک گوگل قرار است اواخر امسال منتشر شود. این بدان معنی است که نه تنها فناوری در هر دو طرف میدان نبرد بهتر می شود (مولدهای محتوا در مقابل موتورهای جستجو)، بلکه استفاده از ترکیب ها آسان تر خواهد بود.
آیا گوگل می تواند محتوای ایجاد شده توسط Sparrow یا GPT-4 را شناسایی کند؟ شاید.
اما اگر با Sparrow تولید شده باشد و سپس با یک اعلان بازنویسی به GPT-4 ارسال شود چطور؟
عامل دیگری که باید به خاطر داشت این است که تکنیک های مورد استفاده در این مقاله بر اساس مدل های خود رگرسیون است. به زبان ساده، آنها امتیازی را برای یک کلمه بر اساس آنچه که آن کلمه را پیشبینی میکنند پیشبینی میکنند تا به کلمات قبل از آن داده شود.
از آنجایی که مدلها درجه بالاتری از پیچیدگی را ایجاد میکنند و شروع به خلق ایدههای کامل در یک زمان میکنند تا یک کلمه به دنبال کلمه دیگر، تشخیص هوش مصنوعی ممکن است دچار مشکل شود.
از سوی دیگر، تشخیص محتوای ساده و مزخرف باید تشدید شود – که ممکن است به این معنی باشد که تنها محتوای “کیفیت پایین” که برنده خواهد شد، تولید شده توسط هوش مصنوعی است.
نظرات بیان شده در این مقاله نظرات نویسنده مهمان است و لزوماً سرزمین موتور جستجو نیست. نویسندگان کارکنان در اینجا فهرست شده اند.